 Zhuoli's Blog
Zhuoli's Blog上篇文章讲了EnumMap的实现,本篇文章按照惯例,介绍一下存储枚举类型集合Set类——EnumSet。但是跟之前HashSet和HashMap、TreeSet和TreeMap的关系不同,EnumSet不是依靠EnumMap实现的,甚至可以讲,实现方式跟EnumMap完全没有关系。另外和HashSet、TreeSet不同的是,EnumSet是抽象类,而HashSet、TreeSet是非抽象的。EnumMap的继承关系如下:
EnumSet继承了AbstractSet抽象类,表名EnumSet是支持基础的Set操作的,其它的方法都定义在EnumSet类中。
1. 调用示例
EnumSet是抽象类,所以不能通过构造函数构造EnumSet对象。在Java API中EnumSet抽象类有两个实现,分别是RegularEnumSet和JumboEnumSet。EnumSet中提供了很多静态方法,可以构造上述两个实现类的实例。
Set<SizeEnum> enumSet0 = EnumSet.allOf(SizeEnum.class);
System.out.print("EnumSet.allOf: ");
System.out.println(enumSet0);
System.out.print("EnumSet.noneOf: ");
Set<SizeEnum> enumSet1 = EnumSet.noneOf(SizeEnum.class);
System.out.println(enumSet1);
System.out.print("add item LARGE MEDIUM EXTRA_LARGE: ");
enumSet1.add(SizeEnum.LARGE);
enumSet1.add(SizeEnum.MEDIUM);
enumSet1.add(SizeEnum.EXTRA_LARGE);
System.out.println(enumSet1);
System.out.print("EnumSet.of LARGE SMALL: ");
Set<SizeEnum> enumSet2 = EnumSet.of(SizeEnum.LARGE, SizeEnum.SMALL);
System.out.println(enumSet2);运行结果如下:
EnumSet.allOf: [SMALL, MEDIUM, LARGE, EXTRA_LARGE]
EnumSet.noneOf: []
add item LARGE MEDIUM EXTRA_LARGE: [MEDIUM, LARGE, EXTRA_LARGE]
EnumSet.of LARGE SMALL: [SMALL, LARGE]可以发现的是,EnumSet中提供了一些静态方法,构造EnumSet实例,至于具体方法,下面讲解。还有就是,EnumSet也可以保证元素之间按照枚举类中枚举值的定义有序。下面通过一个例子,看一下EnumSet的具体应用:
//库存详情类
@Getter
@Setter
@AllArgsConstructor
public class StockInfo {
//库存商品id
private Long productId;
//库存商品id对应的尺码
private Set<SizeEnum> stockSizes;
}List<StockInfo> stockInfoList = Lists.newArrayList();
stockInfoList.add(new StockInfo(1L, EnumSet.of(SizeEnum.SMALL, SizeEnum.MEDIUM, SizeEnum.EXTRA_LARGE)));
stockInfoList.add(new StockInfo(2L, EnumSet.of(SizeEnum.SMALL, SizeEnum.MEDIUM, SizeEnum.EXTRA_LARGE)));
stockInfoList.add(new StockInfo(3L, EnumSet.of(SizeEnum.SMALL, SizeEnum.EXTRA_LARGE)));
stockInfoList.add(new StockInfo(4L, EnumSet.of(SizeEnum.SMALL, SizeEnum.MEDIUM)));
System.out.print("这些型号的商品有库存: ");
Set<SizeEnum> allSizeEnum0 = EnumSet.noneOf(SizeEnum.class);
stockInfoList.forEach(ele -> {
allSizeEnum0.addAll(ele.getStockSizes());
});
System.out.println(allSizeEnum0);
System.out.print("这些型号的商品没有库存: ");
Set<SizeEnum> allSizeEnum1 = EnumSet.allOf(SizeEnum.class);
stockInfoList.forEach(ele -> {
allSizeEnum1.removeAll(ele.getStockSizes());
});
System.out.println(allSizeEnum1);
System.out.print("这些型号所有的商品都有库存: ");
Set<SizeEnum> allSizeEnum2 = EnumSet.allOf(SizeEnum.class);
stockInfoList.forEach(ele -> {
allSizeEnum2.retainAll(ele.getStockSizes());
});
System.out.println(allSizeEnum2);
System.out.print("这些型号至少有三种商品有库存: ");
Map<SizeEnum, Integer> sizeCountMap = Maps.newEnumMap(SizeEnum.class);
stockInfoList.forEach(ele -> {
ele.getStockSizes().forEach(size -> {
sizeCountMap.compute(size, (k, v) -> Objects.isNull(v) ? 1 : ++v);
});
});
Map<SizeEnum, Integer> finalSizeMap = sizeCountMap.entrySet().stream().filter(ele -> ele.getValue() >= 3)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(finalSizeMap);运行结果:
这些型号的商品有库存: [SMALL, MEDIUM, EXTRA_LARGE]
这些型号的商品没有库存: [LARGE]
这些型号所有的商品都有库存: [SMALL]
这些型号至少有三种商品有库存: {MEDIUM=3, SMALL=4, EXTRA_LARGE=3}通过EnumSet,可以很方便的处理枚举类型数据集合。
2. 方法说明
2.1 EnumSet构造对象方法
上面讲过EnumSet是抽象类,不能通过构造函数构造实例,但是提供了很多静态方法,构造EnumSet实例,如下:
| S.N. | 方法 | 说明 |
|---|---|---|
| 1 | public static <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) | 构造一个包含elementType枚举类所有枚举值的EnumSet对象 |
| 2 | public static <E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s) | 构造EnumSet s的补集EnumSet对象 |
| 3 | public static <E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c) | 通过集合c构建EnumSet对象,EnumSet中包括c中所有元素 |
| 4 | public static <E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s) | 通过EnumSet s构建EnumSet对象,EnumSet中包括s中所有元素 |
| 5 | public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) | 构建一个元素类型为elementType对应的枚举类型的空EnumSet对象 |
| 6 | public static <E extends Enum<E>> EnumSet<E> of(E e) | 构建一个单值EnumSet对象 |
| 7 | public static <E extends Enum<E>> EnumSet<E> of(E e1, E e2) | 构建一个包含两个元素的EnumSet对象 |
| 8 | public static <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3) | 构建一个包含三个元素的EnumSet对象 |
| 9 | public static <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4) | 构建一个包含四个元素的EnumSet对象 |
| 10 | public static <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4, E e5) | 构建一个包含五个元素的EnumSet对象 |
| 11 | public static <E extends Enum<E>> EnumSet<E> of(E first, E… rest) | 构建一个包含n个元素的EnumSet对象 |
| 12 | public static <E extends Enum<E>> EnumSet<E> range(E from, E to) | 构建一个区间为from到to中所有枚举值组成的EnumSet对象,区间左闭右闭 |
2.2 Set接口
| S.N. | 方法 | 说明 |
|---|---|---|
| 1 | boolean add(E e) | 向Set中添加一个元素 |
| 2 | boolean addAll(Collection<? extends E> c) | 将Collection中的元素添加到Set中 |
| 3 | boolean contains(Object o) | 判断Set中是否包含o元素 |
| 4 | boolean containsAll(Collection<?> c) | 判断Collection中的元素是否全部存在于Set中 |
| 5 | boolean equals(Object o) | equals方法 |
| 6 | int hashCode() | hashCode方法 |
| 7 | boolean isEmpty() | 判断Set是否为空 |
| 8 | Iterator<E> iterator() | 返回Set的单向Iterator迭代器 |
| 9 | boolean remove(Object o) | 删除Set中的元素o |
| 10 | boolean removeAll(Collection<?> c) | 删除Set中包含的Collection的所有元素,如果c也为Set,表示求差集 |
| 11 | boolean retainAll(Collection<?> c) | 保留Set中包含的Collection的所有元素,如果c也为Set,表示求交集 |
| 12 | int size() | 返回Set元素个数 |
| 13 | default Spliterator<E> spliterator() | 返回Set的并行流Spliterator迭代器 |
| 14 | Object[] toArray() | Set转Object[]数组 |
| 15 | <T> T[] toArray(T[] a) | Set转特定类型数组 |
3. 实现源码分析
3.1 EnumSet类定义
EnumSet在Java API中没有通过EnumMap实现,而是通过位向量实现的。位向量就是用一个bit位表示一个元素的状态,用一个bit数组表示一个元素集合的状态,每个bit位对应一个元素,状态有两种(0和1)。比如上面讲的SizeEnum,通过如下方式定义一个EnumSet对象:
Set<SizeEnum> enums = EnumSet.of(SizeEnum.SMALL, SizeEnum.LARGE, SizeEnum.EXTRA_LARGE);对于枚举类SizeEnum,总共有4个枚举值,所以SizeEnum类型的EnumSet可以使用一个byte表示(因为总共最多就4个元素,一个byte有8个bit),最低位bit对应ordinal最小的枚举值,从右到左,每个bit对应一个枚举值,1表示包含该元素,0表示不含该元素。所以上述EnumSet enums可以表示为:
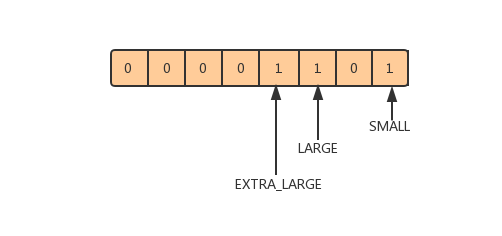 但是EnumSet类中,并没有定义类似的位向量,EnumSet类定义如下:
但是EnumSet类中,并没有定义类似的位向量,EnumSet类定义如下:
public abstract class EnumSet<E extends Enum<E>> extends AbstractSet<E>
implements Cloneable, java.io.Serializable
{
//EnumSet中存储元素对应的枚举类类型
final Class<E> elementType;
//elementType对应的枚举类所有枚举值组成的数组
final Enum<?>[] universe;
//methods
} 这是因为EnumSet中并没有实现像add、remove等操作,只是定义了一些构造EnumSet对象的静态方法,并且这些静态方法都试调用的具体实现类的方法,所以并不需要操作位向量。EnumSet底层实现使用的位向量实在具体实现类RegularEnumSet和JumboEnumSet中定义的,RegularEnumSet和JumboEnumSet的区别在于位向量的长度,如果枚举值个数小于等于64,则静态工厂方法中创建的就是RegularEnumSet,否则构造的就是JumboEnumSet。RegularEnumSet使用一个long类型的变量作为位向量,long类型的bit位长度是64,而JumboEnumSet使用一个long类型的数组表示位向量。
class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
//表示EnumSet元素的位向量位向量,枚举类的枚举值小于等于64时,可以使用RegularEnumSet表示
private long elements = 0L;
//methods
} class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
//表示EnumSet元素的位向量,如果枚举类中枚举值大于64,比如74,elements数组的长度为2
private long elements[];
//EnumSet中元素个数
private int size = 0;
} 3.2 noneOf方法
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
//获取枚举类所有枚举值组成的数组,跟之前讲EnumMap的实现一致
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
//如果枚举类中枚举值小于等于64,则构建RegularEnumSet对象
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
//如果枚举类中枚举值大于64,则构建JumboEnumSet对象
return new JumboEnumSet<>(elementType, universe);
}RegularEnumSet(Class<E>elementType, Enum<?>[] universe) {
super(elementType, universe);
}RegularEnumSet的构造函数,就是对调用了EnumSet中的构造函数,对elementType和universe赋值。
JumboEnumSet(Class<E>elementType, Enum<?>[] universe) {
super(elementType, universe);
elements = new long[(universe.length + 63) >>> 6];
}JumboEnumSet的构造函数,同样调用了EnumSet中的构造函数,对elementType和universe赋值。同时,对JumboEnumSet内部位向量数组初始化。位向量数组elements数组长度计算逻辑为:
(universe.length + 63) >>> 6右移6位,相当于除以64,结果就是表示当前枚举类中所有枚举值所需64位long的个数。比如当前枚举类枚举值个数为80,则结果为2,表示使用两个long(128位)才可以表示80位枚举值。
3.3 allOf方法
public static <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) {
EnumSet<E> result = noneOf(elementType);
result.addAll();
return result;
}构建elementType对应枚举类所有枚举值组成的EnumSet,实现为通过上述noneOf构造一个空的EnumSet对象,然后调用addAll方法,将枚举类中所有枚举值添加到EnumSet中。addAll方法在EnumSet类的实现类RegularEnumSet、JumboEnumSet中有具体实现,在EnumSet中是抽象方法。
3.4 of方法
public static <E extends Enum<E>> EnumSet<E> of(E e) {
EnumSet<E> result = noneOf(e.getDeclaringClass());
result.add(e);
return result;
}构建枚举值e组成的EnumSet
3.5 copyOf方法
public static <E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c) {
if (c instanceof EnumSet) {
return ((EnumSet<E>)c).clone();
} else {
if (c.isEmpty())
throw new IllegalArgumentException("Collection is empty");
Iterator<E> i = c.iterator();
E first = i.next();
EnumSet<E> result = EnumSet.of(first);
while (i.hasNext())
result.add(i.next());
return result;
}
}
public static <E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s) {
return s.clone();
}3.6 add方法
RegularEnumSet中add方法如下:
public boolean add(E e) {
typeCheck(e);
long oldElements = elements;
elements |= (1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}typeCheck方法用来检查待添加的元素e是否为EnumSet的枚举类型枚举值。之前讲过,EnumSet中是通过位向量存储枚举值的,添加一个元素,只要将枚举值的ordinal对应数字位置的位向量改为1,就可以实现。就是通过如下方式实现的:
elements |= (1L << ((Enum<?>)e).ordinal());(1L << ((Enum)e).ordinal())将位向量中元素e对应的位设为1,与现有的位向量elements相或,就表示添加e了。最后如果添加元素前位向量与添加元素后位向量不同,表示元素添加成功了(位向量改变了)。
JumboEnumSet中add方法如下:
public boolean add(E e) {
typeCheck(e);
//元素e的ordinal
int eOrdinal = e.ordinal();
//元素e在位向量中的位在JumboEnumSet中long数组的index(ordinal / 64)
int eWordNum = eOrdinal >>> 6;
//添加元素前,对应段的位向量值
long oldElements = elements[eWordNum];
//移位相或,这点跟RegularEnumSet中一致
elements[eWordNum] |= (1L << eOrdinal);
boolean result = (elements[eWordNum] != oldElements);
//如果元素添加了,将JumboEnumSet中size加1
if (result)
size++;
return result;
}JumboEnumSet的add操作与RegularEnumSet的区别是,JumboEnumSet需要先找到位向量落在数组位置,eOrdinal >>> 6就是eOrdinal除以64,eWordNum就表示elements数组索引,有了索引之后,其他操作跟RegularEnumSet一致。其次还有一点区别是,JumboEnumSet中维护了Set中元素的个数size,而RegularEnumSet中没有这个size,因为RegularEnumSet位向量是固定的(64位),只要统计当前64位中1的个数,就是元素的个数,比较简单。
3.7 addAll方法(并集)
public boolean addAll(Collection<? extends E> c) {
//如果c不是RegularEnumSet,则调用AbstractCollection中的addAll方法
//实现逻辑为调用RegularEnumSet中的add方法,依次添加
if (!(c instanceof RegularEnumSet))
return super.addAll(c);
//如果c为RegularEnumSet,进行类型检查
RegularEnumSet<?> es = (RegularEnumSet<?>)c;
if (es.elementType != elementType) {
if (es.isEmpty())
return false;
else
throw new ClassCastException(
es.elementType + " != " + elementType);
}
long oldElements = elements;
//位向量相或,可以表示求并集,也就是addAll操作
elements |= es.elements;
return elements != oldElements;
}addAll方法的核心就是elements |= es.elements,维向量相或,就是求并集,也就是将es中所有的元素添加到当前EnumSet中。
3.7 remove方法
public boolean remove(Object e) {
//如果待删除元素为null,直接返false
if (e == null)
return false;
//待删除元素类型检查
Class<?> eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
//删除元素前,位向量
long oldElements = elements;
//将e对应位向量中位的值设为0,删除元素
elements &= ~(1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}~是取反,该代码将元素e在位向量中对应的位设为了0,0与任何数相与都是0,这样就可以将e在维向量中对应的位设位0,从而完成了删除操作。从集合的观点来看,remove就是求集合的差,A-B等价于A∩B’,B’表示B的补集。代码中,elements相当于A,(1L << ((Enum)e).ordinal())相当于B,~(1L << ((Enum)e).ordinal())相当于B’,elements &= ~(1L << ((Enum)e).ordinal())就相当于A∩B’,即A-B。
3.8 removeAll方法(差集)
public boolean removeAll(Collection<?> c) {
if (!(c instanceof RegularEnumSet))
return super.removeAll(c);
RegularEnumSet<?> es = (RegularEnumSet<?>)c;
if (es.elementType != elementType)
return false;
long oldElements = elements;
//A-B = A∩B'
elements &= ~es.elements;
return elements != oldElements;
}就是通过上面讲的A-B = A∩B’的原理实现的,跟remove方法实现思想一致。
3.9 contains方法
public boolean contains(Object e) {
if (e == null)
return false;
Class<?> eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
return (elements & (1L << ((Enum<?>)e).ordinal())) != 0;
}e在维向量中的位的值为1,表明e在EnumSet中是存在的,即与操作位1。
3.10 containsAll方法
public boolean containsAll(Collection<?> c) {
if (!(c instanceof RegularEnumSet))
return super.containsAll(c);
RegularEnumSet<?> es = (RegularEnumSet<?>)c;
if (es.elementType != elementType)
return es.isEmpty();
//A⊆B等价于A∩B'=∅
return (es.elements & ~elements) == 0;
}从集合的角度,存在这样一个定理,A⊆B等价于A∩B’=∅。containsAll方法就是判断集合c是否都包含在当前EnumSet中,所以等价于c∩enumSet’=∅。
3.11 retainAll方法(交集)
public boolean retainAll(Collection<?> c) {
if (!(c instanceof RegularEnumSet))
return super.retainAll(c);
RegularEnumSet<?> es = (RegularEnumSet<?>)c;
if (es.elementType != elementType) {
boolean changed = (elements != 0);
elements = 0;
return changed;
}
long oldElements = elements;
//位向量按位与,相当于求交集
elements &= es.elements;
return elements != oldElements;
}3.12 complementOf方法(补集)
在上文讲EnumSet时,讲过EnumSet中有一个静态方法complementOf,求当前EnumSet的补集,在EnumSet中实现如下:
public static <E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s) {
//copyOf生成一个新的副本,避免对集合的操作影响当前集合
EnumSet<E> result = copyOf(s);
//调用complement方法求补集
result.complement();
return result;
}EnumSet中complement是个抽象方法,在RegularEnumSet和JumboEnumSet中有各自的实现。下面看一下RegularEnumSet中complement方法的实现:
void complement() {
if (universe.length != 0) {
//位向量取反求补集
elements = ~elements;
//将当前枚举类用不到的高位位向量设为0
elements &= -1L >>> -universe.length; // Mask unused bits
}
}elements=~elements比较容易理解,就是按位取反,相当于就是取补集,因为elements是64位的,当前枚举类有可能没有64个枚举值,取反后高位部分都变为了1,需要将超出universe.length的部分设为0。下面代码就是在做这件事:
elements &= -1L >>> -universe.length;-1L是64位全1的二进制,上面代码相当于:
elements &= -1L >>> (64-universe.length); 如果universe.length为16,则-1L>>>(64-16)就是二进制的0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111,与elements相与,就会将超出universe.length部分的右边的48位都变为0。
4. EnumSet特点
EnumSet没有使用EnumMap实现,而是通过位向量实现,大部分操作都是按位运算,计算机位计算效率极高。
参考链接:
- Java API源码