 Zhuoli's Blog
Zhuoli's Blog在介绍Java中的HashSet之前,我们首先来看一下数学上集合的特性:
- 无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。集合上可以定义序关系,定义了序关系后,元素之间就可以按照序关系排序。但就集合本身的特性而言,元素之间没有必然的序。
- 互异性:一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现一次。有时需要对同一元素出现多次的情形进行刻画,可以使用多重集,其中的元素允许出现多次。
- 确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。
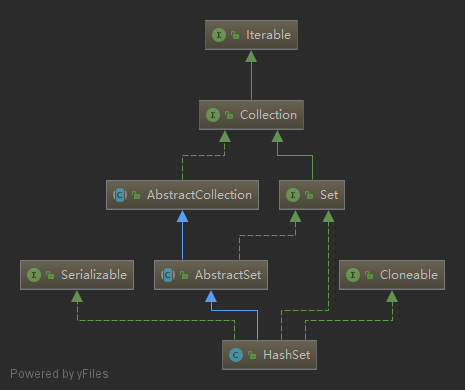
Java中的Set概念上跟数学上的集合完全一致,也具有上述特性。了解了上节HashMap的实现后,再来看HashSet的实现就比较简单了,因为HashSet底层就是通过HashMap实现的,HashSet可以理解为一种value全为Object的HashMap,HashMap所有的key表示集合中的元素。HashSet实现了Set接口,集成了AbstractSet抽象类,同时实现了Serializable、Cloneable接口,如下图所示:
1. 使用规则
HashSet在Java API中声明如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
//methods
} HashSet内部是通过HashMap实现的,静态final对象PRESENT是HashMap中所有key对应的默认value。
1.1 构造方法
| S.N. | 方法 | 说明 |
|---|---|---|
| 1 | public HashSet() | 无参构造函数 |
| 2 | public HashSet(Collection<? extends E> c) | 通过一个Collection初始化HashSet |
| 3 | public HashSet(int initialCapacity) | 声明一定容量的HashSet |
| 4 | public HashSet(int initialCapacity, float loadFactor) | 声明一定容量、负载因子的HashSet |
1.2 Set接口
| S.N. | 方法 | 说明 |
|---|---|---|
| 1 | boolean add(E e) | 向Set中添加一个元素 |
| 2 | boolean addAll(Collection<? extends E> c) | 将Collection中的元素添加到Set中 |
| 3 | boolean contains(Object o) | 判断Set中是否包含o元素 |
| 4 | boolean containsAll(Collection<?> c) | 判断Collection中的元素是否全部存在于Set中 |
| 5 | boolean equals(Object o) | equals方法 |
| 6 | int hashCode() | hashCode方法 |
| 7 | boolean isEmpty() | 判断Set是否为空 |
| 8 | Iterator<E> iterator() | 返回Set的单向Iterator迭代器 |
| 9 | boolean remove(Object o) | 删除Set中的元素o |
| 10 | boolean removeAll(Collection<?> c) | 删除Set中包含的Collection的所有元素,如果c也为Set,表示求差集 |
| 11 | boolean retainAll(Collection<?> c) | 保留Set中包含的Collection的所有元素,如果c也为Set,表示求交集 |
| 12 | int size() | 返回Set元素个数 |
| 13 | default Spliterator<E> spliterator() | 返回Set的并行流Spliterator迭代器 |
| 14 | Object[] toArray() | Set转Object[]数组 |
| 15 | <T> T[] toArray(T[] a) | Set转特定类型数组 |
2. 实现源码分析
HashSet实现比较简单,底层是通过HashMap实现的,只不过HashMap所有的value都是同一个Object对象。
2.1 构造函数
//调用HashMap默认构造函数,HashMap capacity为16,loadFactor为0.75
public HashSet() {
map = new HashMap<>();
}
//调用HashMap(int initialCapacity)构造函数,容量为c.size() / 0.75 + 1大小的hashMap
//HashMap负载因子仍为0.75,如果c.size() / 0.75 + 1 < 16,则容量定义为16
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//调用HashMap(int initialCapacity)构造函数,声明容量为initialCapacity大小的HashMap
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//调用HashMap(int initialCapacity, float loadFactor),声明特定容量和负载因子的HashMap
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}2.2 boolean add(E e)
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}就是调用HashMap的put方法,元素e用于HashMap的键,HashMap的值就是那个final的Object对象PRESENT,put返回null表示原来没有对应的键,添加成功了。HashMap中一个键只会保存一份,这也能解释为什么HashSet可以保证键不重复的原因。这里还要特别提一下,HashMap中要求key元素类型必须重写hashCode和equals方法,所以HashSet也要求元素重写hashCode和equals方法,如果两个对象,equals相同,则hashCode也必须相同,如果元素是自定义的类,一定要注意重写这两个方法。
2.3 remove(Object o)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
调用HashMap的remove方法,返回值为PRESENT表示原来有对应的键且删除成功了。
2.4 contains(Object o)
public boolean contains(Object o) {
return map.containsKey(o);
}调用HashMap的containsKey方法,判断key o是不是存在。
3. HashSet特点
HashSet实现了Set接口,内部是通过HashMap实现的,这也决定了HashSet有如下特点:
- HashSet中可以保证没有重复元素
- 添加、删除、判断元素是否存在,效率很高,时间复杂度为O(1)。
- HashSet无法保证元素顺序
基于以上特点,HashSet一般有以下使用场景:
- 排重,如果对排重后的元素没有顺序要求,则HashSet可以方便的用于排重。
- 集合运算,使用Set可以方便的进行数学集合中的运算,如交集、并集等运算
参考链接:
- Java API