 Zhuoli's Blog
Zhuoli's Blog上篇文章中简单介绍了文件和Java IO的概念,我们了解到Java中文件是作为一种特殊的IO设备处理的,并且Java中处理IO是通过流来操作的,流又可以细分为字节流和字符流。本篇文章就重点介绍一下Java IO中的一个重要模块——字节流。字节流的继承体系如下图所示:
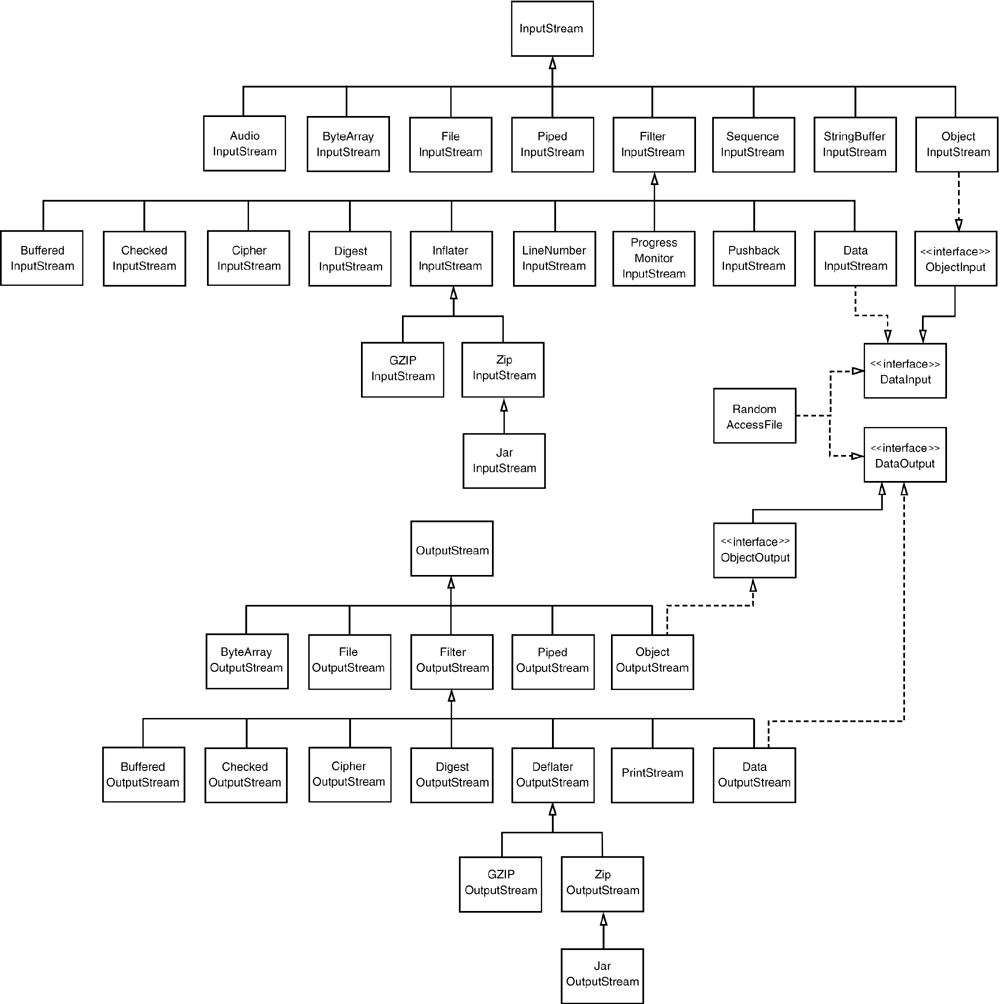
本文重点介绍如下几种字节流:
- InputStream/OutputStream: 基类,抽象类。
- ByteArrayInputStream/ByteArrayOutputStream: 输入源和输出目标是字节数组的流。
- FileInputStream/FileOutputStream: 输入源和输出目标是文件的流。
- FilterInputStream/FilterOutputStream,所有包装流的父类,一些“特殊”功能的流,比如DataInputStream/DataOutputStream、BufferedInputStream/BufferedOutputStream都继承了改类。
- ObjectInputStream/ObjectOuputStream:输入源和输出目标是对象的流,用于实现Java序列化。
1. InputStream/OutputStream
InputStream和OutputStream是抽象类,是所有字节流的基类。
1.1 InputStream
| S.N. | 方法 | 说明 |
| 1 | public abstract int read() throws IOException | 从字节输入流中读取下一个字节,返回值为读取字节的int值 |
| 2 | public int read(byte b[]) throws IOException | 从字节输入流中读取多个字节,放入字节数组b中,返回值为实际读入的字节个数 |
| 3 | public int read(byte b[], int off, int len) throws IOException | 从字节输入流中读取len个字节放入字节数组b index off开始的位置, 返回值为实际读入的字节个数 |
| 4 | public void close() throws IOException | 关闭字节输入流,释放资源 |
| 5 | public long skip(long n) throws IOException | 跳过字节输入流中n个字节,返回值为实际跳过的字节个数 |
| 6 | public int available() throws IOException | 返回下一次不需要阻塞就能读取到的字节个数,使用较少 |
| 7 | public synchronized void mark(int readlimit) | 标记能够从字节输入流中往后读取的字节个数readlimit |
| 8 | public boolean markSupported() | 判断当前字节输入流是否支持mark/reset操作 |
| 9 | public synchronized void reset() throws IOException | 重新从标记位置读取字节输入流 |
- read()
read()方法会从字节输入流中读取下一个字节,返回类型为int(一个字节8位,范围0~255,所以int可以表示),当读到流结尾的时候,返回值为-1。如果字节输入流中没有数据,read方法会阻塞直到数据到来、流关闭、或异常出现。异常出现时,read方法抛出异常,类型为IOException,这是一个受检异常,调用者必须进行处理。read是一个抽象方法,具体子类必须实现。
- read(byte b[])
read(byte b[])方法将从字节输入流读入的字节放入字节数组b中,第一个字节存入b[0],第二个存入b[1],以此类推,一次最多读入的字节个数为数组b的长度,但实际读入的个数可能小于数组长度,返回值为实际读入的字节个数。如果刚开始读取时已到流结尾,则返回-1,否则,只要数组长度大于0,该方法都会尽力至少读取一个字节,如果流中一个字节都没有,它也会阻塞直到数据到来、流关闭、或异常出现。该方法不是抽象方法,InputStream有一个默认实现,通过调用读一个字节的read方法实现,但子类中一般会提供更为高效的实现。
- read(byte b[], int off, int len)
read(byte b[], int off, int len)方法会将读入的第一个字节放入b[off],最多读取len个字节。read(byte b[])方法就是调用这个方法实现的,如下:
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}- close()
close()方法作用是字节输入流读取结束后,关闭流,释放相关资源。不管read方法是否抛出了异常,都应该调用close方法,所以close通常应该放在finally语句内。该方法不是抽象方法,InputStream中的实现是一个空函数,子类中会提供自己的实现。
- skip()
skip()方法会跳过字节输入流中n个字节,因为输入流中剩余的字节个数可能不到n,所以返回值为实际略过的字节个数。InputStream的默认实现就是调用readd()方法,尽力读取n个字节,实现skip效果。子类往往会提供更为高效的实现,比如在FileInputStream中会调用本地方法。在处理数据时,对于不感兴趣的部分,skip往往比读取然后扔掉的效率要高。
- available()
available()方法返回下一次不需要阻塞就能读取到的字节个数。InputStream的默认实现是返回0,子类会根据具体情况返回适当的值。在文件读写中,这个方法一般没什么用,但在从网络读取数据时,可以根据该方法的返回值在网络有足够数据时才读,以避免阻塞。
- mark(int readlimit)
mark(int readlimit)方法用于标记当前字节输入流读取的位置,当字节输入流已经读取过该位置后,可以通过调用reset()方法,重新从标记位置读取。readLimit,表示在设置了标记后,能够继续往后读的最多字节数,如果超过了,标记会无效。因为之所以能够重读,是因为流能够将从标记位置开始的字节保存起来,而保存消耗的内存不能无限大,流只保证不会小于readLimit。在InputStream中该方法是个空方法,具体子类要根据自身情况覆盖该方法。
- markSupported()
markSupported()方法用于获取当前字节输入流是否支持mark/reset操作,返回true表示当前字节输入流支持mark/reset操作。InpuStream类中的默认实现是不支持,子类根据自身情况覆盖该方法。
- reset()
reset()方法用于重新从mark标记位置读取字节输入流。
1.2 OutputStream
| S.N. | 方法 | 说明 |
| 1 | public abstract void write(int b) throws IOException | 向字节输出流中写入一个字节 |
| 2 | public void write(byte b[]) throws IOException | 将字节数组b中所有的字节写入字节输出流 |
| 3 | public void write(byte b[], int off, int len) throws IOException | 将字节数组b中从index off开始,长度为len的字节写入字节输出流 |
| 4 | public void flush() throws IOException | 将缓冲而未实际写的数据进行实际写入 |
| 5 | public void close() throws IOException | 关闭字节输出流,释放资源 |
- write(int b)
write(int b)方法向流中写入一个字节,参数类型虽然是int,但其实只会用到最低的8位(一个字节)。该方法在OutputStream中是个抽象方法,子类需要根据自身情况实现该方法。
- write(byte b[], int off, int len)
write(byte b[], int off, int len)方法会将字节数组中index从off开始的len个字节写入到字节输出流中,第一个写入的字节是b[off],写入个数为len,最后一个是b[off+len-1]。OutputStream的默认实现是循环调用单字节的write方法,子类往往有更为高效的实现。
- write(byte b[])
write(byte b[])方法会将字节数组中的全部字节写入到字节输出流中,在OutputStream中的实现是write(b, 0, b.length)。
- flush()
flush()方法会将缓冲而未实际写的数据进行实际写入。
- close()
close()方法会关闭字节输出流,释放系统资源。
2. ByteArrayInputStream/ByteArrayOutputStream
2.1 ByteArrayInputStream
ByteArrayInputStream的作用是将byte数组包装为一个输入流(适配器模式 )。ByteArrayInputStream可以通过如下两种方式构建:
public ByteArrayInputStream(byte buf[]);
public ByteArrayInputStream(byte buf[], int offset, int length);第一个构造函数是将字节数组buf中的全部字节包装到ByteArrayInputStream(效果是buf数组中的全部字节都体现在ByteArrayInputStream中)。第二个构造函数是将字节数组buf中index从offset开始长度为length的所有字节包装到ByteArrayInputStream(效果是buf数组中offset到offset + len -1的字节体现在ByteArrayInputStream中,read操作也只能读取到offset及之后的字节)。ByteArrayInputStream的所有数据都在内存,支持mark/reset重复读取。
2.2 ByteArrayOutputStream
ByteArrayOutputStream的作用是将内存中的数据输出到一个byte数组中,充当这个输出操作的“管道”。ByteArrayOutputStream可以通过如下两种方式构建:
public ByteArrayOutputStream();
public ByteArrayOutputStream(int size);第二个构造函数中的size是用来存储内存中数据的字节数组的大小。第一个构造函数的实现是通过调用第二个构造函数实现的,size默认为32。在调用write方法向ByteArrayOutputStream流中写值的过程中,如果字节数组长度不够,会进行动态扩容,扩展后的容量是扩容前容量的两倍。
| S.N. | 方法 | 说明 |
| 1 | public synchronized byte[] toByteArray() | 将ByteArrayOutputStream流中的内容输出到字节数组 |
| 2 | public synchronized String toString() | 以系统默认编码,将ByteArrayOutputStream流中的内容(write操作写进来字节数组)输出为字符串 |
| 3 | public synchronized String toString(String charsetName) | 使用特定编码,将ByteArrayOutputStream流中的内容(write操作写进来字节数组)输出为字符串 |
| 4 | public synchronized void writeTo(OutputStream out) throws IOException | 将ByteArrayOutputStream中的数据写到另一个OutputStream中 |
| 5 | public synchronized int size() | 返回当前已经写入的字节个数 |
| 6 | public synchronized void reset() | 重置ByteArrayOutputStream中的内容,之前写入的内容都会无效 |
2.3 使用示例
@SneakyThrows
public static void main(String[] args) {
byte[] bytes = Bytes.toArray(Lists.newArrayList(65, 66, 67, 68));
try (InputStream inputStream = new ByteArrayInputStream(bytes);
ByteArrayOutputStream output = new ByteArrayOutputStream()) {
writeStream(inputStream, output);
}
try (InputStream inputStream = new ByteArrayInputStream(bytes, 1, 2);
ByteArrayOutputStream output = new ByteArrayOutputStream()) {
writeStream(inputStream, output);
}
}
private static void writeStream(InputStream inputStream, ByteArrayOutputStream output) throws IOException {
byte[] buf = new byte[16];
int bytesRead;
while ((bytesRead = inputStream.read(buf)) != -1) {
output.write(buf, 0, bytesRead);
}
String data = output.toString("UTF-8");
System.out.println(data);
}输出结果:
ABCD
BC关于上面这段代码,简单讲述一下:
- Bytes.toArray()方法是google Guava工具包提供的方法,代码中的作用是将List<Integer>转化为一个byte数组,详见之前的一篇文章Guava元语工具
- try () {}这种格式是Java8提供的语法糖try-with-resource,可以在try代码块执行结束,自动关闭打开的资源
- 两个try代码块,分别测试了ByteArrayInputStream的两种构造函数,根据运行结果,可以发现是符合预期的,第一个ByteArrayInputStream对象通过整个byte数组构造,第二个ByteArrayInputStream对象通过byte数组index 1开始到index 2结束的字节构建
- output.write操作将从ByteArrayInputStream中读取的字节数组写入到ByteArrayOutputStream对象output中
- output.toString(“UTF-8”)使用UTF-8编码将ByteArrayOutputStream中的内容输出为字符串
3. FileInputStream/FileOutputStream
3.1 FileInputStream
FileInputStream是文件和内存之间交互的“水管”,是一种将文件读入到内存中的工具流。可以通过如下两种方式构造:
public FileInputStream(String name) throws FileNotFoundException
public FileInputStream(File file) throws FileNotFoundException其中第一个构造函数的参数是文件路径,第二个构造函数的参数是文件对象。其中文件路径和文件必须是一个存在的文件,并且不能是目录,否则会抛FileNotFoundException。下面通过一个简单的例子看一下FileInputStream的用法:
@SneakyThrows
public static void main(String[] args) {
try (InputStream input = new FileInputStream("d:/hello.txt")) {
byte[] buf = new byte[1024];
int b;
int bytesRead = 0;
while ((b = input.read()) != -1) {
buf[bytesRead++] = (byte) b;
}
String data = new String(buf, 0, bytesRead, StandardCharsets.UTF_8);
System.out.println(data);
}
try (InputStream input = new FileInputStream(new File("d:/hello.txt"))) {
byte[] buf = new byte[1024];
int bytesRead = input.read(buf);
String data = new String(buf, 0, bytesRead, StandardCharsets.UTF_8);
System.out.println(data);
}
try (InputStream input = new FileInputStream(new File("d:/hello.txt"));
ByteArrayOutputStream output = new ByteArrayOutputStream()) {
byte[] buf = new byte[1024];
int bytesRead;
while ((bytesRead = input.read(buf)) != -1) {
output.write(buf, 0, bytesRead);
}
String data = output.toString("UTF-8");
System.out.println(data);
}
}代码逻辑很简单,作用就是通过FileInputStream读取文件,然后将文件内容作为String打印输出。上述三个try代码块分别表示三种实现方式。
- 第一种方式通过逐个字节读取的方式,将FileInputStream流中的内容读取到字节数组buf中,这种方式没有缓存,逐个字节读取,效率较差,且建立在文件内容小于1024个字节的前提下。最后通过String的构造函数,将buf数组转化为String。
- 第二种方式通过FileInputStream的一次read操作,将FileInputStream流中的内容读取到字节数组buf中,这种方式较第一种方式效率上会好一些,但是依然建立在文件内容小于1024个字节的前提下。最后通过String的构造函数,将buf数组转化为String。
- 第三种方式借助ByteArrayOutputStream,每次从FileInputSteam流中读取1024个字节到字节数组buf中,然后再将字节数组内容写入到ByteArrayOutputStream中,由于ByteArrayOutputStream支持动态扩容,不用像之前两种方式那样,依赖于文件内容的大小,所以这种方式是一种比较合理的方式。
3.2 FileOutputStream
FileOutputStream的作用是充当内存到文件之间的“管道”,可以方便地将内存中的数据写入到文件中,可以通过如下几种方式构造:
public FileOutputStream(File file) throws FileNotFoundException
public FileOutputStream(File file, boolean append) throws FileNotFoundException
public FileOutputStream(String name) throws FileNotFoundException
public FileOutputStream(String name, boolean append) throws FileNotFoundException可以通过两种方式构造FileOutPutStream对象,一种是File对象(必须是文件,不是文件路径),另一种是文件路径(路径可以是绝对路径,也可以是相对路径)。如果文件已存在,参数append指定是追加还是覆盖,true表示追加,false表示覆盖(没有append参数地构造函数,append默认为false,表示覆盖文件)。下面通过一个简单地例子来看一下FileOutPutStream地用法:
@SneakyThrows
public static void main(String[] args) {
try (OutputStream output = new FileOutputStream(new File("d:/hello1.txt"))) {
String str = "卓立123";
byte[] bytes = str.getBytes(Charset.forName("UTF-8"));
output.write(bytes);
}
}首先通过getBytes方法将内存中的字符串转化为byte数组,然后调用FileOutPutStream对象的write方法,将byte数组的内容写入到文件中,比较简单,这里就不多讲了。
3. FilterInputStream/FilterOutputStream
上面讲的流,基本的流按字节读写,没有缓冲区,这不方便使用,Java解决这个问题的方法是使用装饰器设计模式。FilterInputStream/FilterOutputStream是所有装饰流的父类,通过名称也能大概猜出FilterInputStream/FilterOutputStream是干嘛的,就是过滤的意思,类似于自来水管道,流入的是水,流出的也是水,功能不变,或者只是增加功能,它有很多子类:
- DataInputStream/DataOutputStream:按八种基本类型和字符串对流进行读写
- BufferedInputStream/BufferedOutputStream:对基础流进行缓冲读写
3.1 DataInputStream/DataOutputStream
3.1.1 DataInputStream
DataInputStream是装饰类FilterInputStream的子类,可以方便地对被包装流中的数据通过基础数据类型读取。由于DataInputStream的作用是对其它字节输入流做包装,所以构造函数中肯定事要传入被包装流的对象的,JDK实现也是这样,如下:
public DataInputStream(InputStream in)除了基础的read方法外,DataInputStream中也提供了针对基本数据类型的读取方法,如下:
| S.N. | 方法 | 说明 |
| 1 | public final int read(byte b[]) throws IOException | 从被包装字节输入流中读取多个字节,放入字节数组b中,返回值为实际读入的字节个数 |
| 2 | public final int read(byte b[], int off, int len) throws IOException | 从被包裝字节输入流中读取len个字节放入字节数组b index off开始的位置, 返回值为实际读入的字节个数 |
| 3 | public final boolean readBoolean() throws IOException | 从被包裝字节输入流中读取一个字节,并转化为boolean输出 |
| 4 | public final byte readByte() throws IOException | 从被包裝字节输入流中读取一个字节输出 |
| 5 | public final char readChar() throws IOException | 从被包裝字节输入流中读取两个字节,并转化为char输出 |
| 6 | public final double readDouble() throws IOException | 从被包裝字节输入流中读取八个字节,并转化为double输出 |
| 7 | public final float readFloat() throws IOException | 从被包裝字节输入流中读取四个字节,并转化为float输出 |
| 8 | public final int readInt() throws IOException | 从被包裝字节输入流中读取四个字节,并转化为int输出 |
| 9 | public final long readLong() throws IOException | 从被包裝字节输入流中读取八个字节,并转化为long输出 |
| 10 | public final short readShort() throws IOException | 从被包裝字节输入流中读取两个字节,并转化为short输出 |
| 11 | public final int readUnsignedByte() throws IOException | 从被包裝字节输入流中读取一个字节,以无符号byte输出 |
| 12 | public final int readUnsignedShort() throws IOException | 从被包裝字节输入流中读取两个字节,并转化为无符号short输出 |
| 13 | public final String readUTF() throws IOException | 读取在已使用UTF-8修改版格式编码的字符串(就是使用DataOutputStream的writeUTF写入的) |
3.1.2 DataOutputStream
DataOutputStream是装饰类FilterOutputStream的子类,可以方便地将内存中的数据通过基础数据类型写入到被包装流的输出目标中。比如被包装流是FileOutputStream对象,那么调用dataOutputSream的writeInt操作,就可以将一个int值写入到FileOutputStream对象的目标文件中。DataOutputStream可以通过如下方式构建:
public DataOutputStream(OutputStream out)除了构造函数,DataOutputStream提供如下写操作:
| S.N. | 方法 | 说明 |
| 1 | public synchronized void write(int b) throws IOException | 写入一个字节 |
| 2 | public synchronized void write(byte b[], int off, int len) | |
| 3 | public final void writeBoolean(boolean v) throws IOException | 写入一个字节,如果值为true,则写入1,否则0 |
| 4 | public final void writeByte(int v) throws IOException | |
| 5 | public final void writeBytes(String s) throws IOException | |
| 6 | public final void writeChar(int v) throws IOException | |
| 7 | public final void writeChars(String s) throws IOException | |
| 8 | public final void writeDouble(double v) throws IOException | |
| 9 | public final void writeFloat(float v) throws IOException | |
| 10 | public final void writeInt(int v) throws IOException | 写入四个字节,最高位字节先写入,最低位最后写入 |
| 11 | public final void writeLong(long v) throws IOException | |
| 12 | public final void writeShort(int v) throws IOException | |
| 13 | public final void writeUTF(String str) throws IOException | 将字符串的UTF-8编码字节写入,这个编码格式与标准的UTF-8编码略有不同 |
3.1.3 示例
定义一个简单实体类Student:
@Getter
@Setter
@AllArgsConstructor
@ToString
public class Student {
private String name;
private int age;
private float grade;
}通过DataInputStream和DataOutputStream进行读写如下:
@SneakyThrows
public static void main(String[] args) {
try (OutputStream fileOutputStream = new FileOutputStream("d:/hello.txt");
DataOutputStream dataOutputStream = new DataOutputStream(fileOutputStream)
) {
List<Student> listStudent = new ArrayList<>();
listStudent.add(new Student("Alice", 23, 80.5f));
listStudent.add(new Student("Brian", 22, 95.0f));
listStudent.add(new Student("Carol", 21, 79.8f));
for (Student student : listStudent) {
dataOutputStream.writeUTF(student.getName());
dataOutputStream.writeInt(student.getAge());
dataOutputStream.writeFloat(student.getGrade());
}
}
try (InputStream fileInputStream = new FileInputStream("d:/hello.txt");
DataInputStream dataInputStream = new DataInputStream(fileInputStream)
) {
List<Student> listStudent = new ArrayList<>();
try {
while (true) {
String name = dataInputStream.readUTF();
int age = dataInputStream.readInt();
float grade = dataInputStream.readFloat();
Student student = new Student(name, age, grade);
listStudent.add(student);
}
} catch (EOFException ex) {
//流读取完毕
}
System.out.println(listStudent);
}
}运行结果:
[Student(name=Alice, age=23, grade=80.5), Student(name=Brian, age=22, grade=95.0), Student(name=Carol, age=21, grade=79.8)]使用DataInputStream/DataOutputStream读写对象,非常灵活,但比较麻烦,所以Java提供了序列化机制ObjectInputSream/ObjectOutputStream。
3.2 BuffedInputStream/BuffedOutputStream
3.2.1 BuffedInputStream
BuffedInputStream是装饰类FilterInputStream的子类,提供普通流读取的缓冲功能,举个例子,如果普通的流是个水管,那么BuffedInputStream就是一个蓄水池。BufferedInputStream内部有个字节数组作为缓冲区,读取时,先从这个缓冲区读,缓冲区读完了再调用包装的流读,可以通过如下两种方式构造:
public BufferedInputStream(InputStream in)
public BufferedInputStream(InputStream in, int size)InputStream表示被包装流,第二个构造函数中的size表示用来缓冲的数组的大小。如果没指定size,那么缓冲数组长度默认为8192。
除了构造方法之外,BuffedInputStream重写了InputStream的read方法,没有提供其他自定义方法。
| S.N. | 方法 | 说明 |
| 1 | public synchronized int read() throws IOException | 从BuffedInputStream中读取下一个字节,返回值为读取字节的int值 |
| 3 | public synchronized int read(byte b[], int off, int len) throws IOException | 从BuffedInputStream中读取len个字节放入字节数组b index off开始的位置, 返回值为实际读入的字节个数 |
| 4 | public void close() throws IOException | 关闭BuffedInputStream,释放资源 |
| 5 | public long skip(long n) throws IOException | 跳过BuffedInputStream中n个字节,返回值为实际跳过的字节个数 |
| 6 | public synchronized int available() throws IOException | 返回下一次不需要阻塞就能读取到的字节个数,使用较少 |
| 7 | public synchronized void mark(int readlimit) | 标记能够从字节输入流中往后读取的字节个数readlimit |
| 8 | public boolean markSupported() | 默认返回true,BufferedInputSream支持mark/reset操作 |
| 9 | public synchronized void reset() throws IOException | 重新从标记位置读取字节输入流 |
3.2.1 BuffedOutputStream
BufferedOutputStream是装饰类FilterOutputStream的子类,提供普通流读取的缓冲功能,同BufferedInputStream类似,BufferedOutputStream也可以通过如下两种构建:
public BufferedOutputStream(OutputStream out)
public BufferedOutputStream(OutputStream out, int size)| S.N. | 方法 | 说明 |
| 1 | public synchronized void write(int b) throws IOException | 向BufferedOutputStream中写入一个字节 |
| 3 | public synchronized void write(byte b[], int off, int len) throws IOException | 将字节数组b中从index off开始,长度为len的字节写入BufferedOutputStream |
| 4 | public void flush() throws IOException | 将缓冲而未实际写的数据进行实际写入 |
3.2.3 示例
@SneakyThrows
public static void main(String[] args) {
try (OutputStream fileOutputStream = new FileOutputStream("d:/hello.txt");
BufferedOutputStream bufferedInputStream = new BufferedOutputStream(fileOutputStream);
DataOutputStream dataOutputStream = new DataOutputStream(bufferedInputStream)
) {
List<Student> listStudent = new ArrayList<>();
listStudent.add(new Student("Alice", 23, 80.5f));
listStudent.add(new Student("Brian", 22, 95.0f));
listStudent.add(new Student("Carol", 21, 79.8f));
for (Student student : listStudent) {
dataOutputStream.writeUTF(student.getName());
dataOutputStream.writeInt(student.getAge());
dataOutputStream.writeFloat(student.getGrade());
}
}
try (InputStream fileInputStream = new FileInputStream("d:/hello.txt");
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
DataInputStream dataInputStream = new DataInputStream(bufferedInputStream)
) {
List<Student> listStudent = new ArrayList<>();
try {
while (true) {
String name = dataInputStream.readUTF();
int age = dataInputStream.readInt();
float grade = dataInputStream.readFloat();
Student student = new Student(name, age, grade);
listStudent.add(student);
}
} catch (EOFException ex) {
//流读取完毕
}
System.out.println(listStudent);
}
}跟上节示例目标一致,通过DataOutputStream向文件中写入对象,然后通过DataInputStream从文件中读取对象。但是上节的示例中,读写文件都是直接读写的,比如readInt操作,就要一个字节一个字节的从FileInputStream中读取内容,效率时不高的。如果像本节示例中,通过BufferedInputStream将FileInputStream对象包装一下,readInt操作就可以从缓冲中读取内容了,BufferedOutputStream操作同样的道理。
4. ObjectInputStream/ObjectOuputStream
ObjectInputStream/ObjectOuputStream是java中用来实现序列化和反序列化默认机制的,从IO流的角度来讲,ObjectInputStream/ObjectOuputStream其实就是源和目标是对象的IO输入输出流。
4.1 ObjectInputStream
ObjectInputStream可以用来实现反序列化,可以通过如下方式构建:
public ObjectInputStream(InputStream in) throws IOException之前讲过DataInputStream可以按照基本数据类型读取流中的内容,比较灵活,但是比较麻烦。相比于DataInputStream,ObjectInputSream也提供了基本数据类型的读取方法,除此之外,ObjectInputSream还提供了readObject方法,ObjectOutputStream通过writeObject方法写入流中的对象。
| S.N. | 方法 | 说明 |
| 1 | public int read() throws IOException | 从ObjectInputSream中读取一个字节 |
| 2 | public int read(byte b[], int off, int len) throws IOException | 从ObjectInputSream中读取len个字节放入字节数组b index off开始的位置, 返回值为实际读入的字节个数 |
| 3 | public boolean readBoolean() throws IOException | 从ObjectInputSream中读取一个字节,并转化为boolean输出 |
| 4 | public byte readByte() throws IOException | 从ObjectInputSream中读取一个字节输出 |
| 5 | public char readChar() throws IOException | 从ObjectInputSream中读取两个字节,并转化为char输出 |
| 6 | public double readDouble() throws IOException | 从ObjectInputSream中读取八个字节,并转化为double输出 |
| 7 | public float readFloat() throws IOException | 从ObjectInputSream中读取四个字节,并转化为float输出 |
| 8 | public int readInt() throws IOException | 从ObjectInputSream中读取四个字节,并转化为int输出 |
| 9 | public long readLong() throws IOException | 从ObjectInputSream中读取八个字节,并转化为long输出 |
| 10 | public final Object readObject() throws IOException, ClassNotFoundException | 反序列化,从ObjectInputSream读取序列化的对象 |
| 11 | public short readShort() throws IOException | 从ObjectInputSream中读取两个字节,并转化为short输出 |
| 12 | public int readUnsignedByte() throws IOException | 从ObjectInputSream中读取一个字节,以无符号byte输出 |
| 13 | public int readUnsignedShort() throws IOException | 从ObjectInputSream中读取两个字节,并转化为无符号short输出 |
| 14 | public String readUTF() throws IOException | 从ObjectInputSream中读取在已使用UTF-8修改版格式编码的字符串(就是使用ObjectOutputSream的writeUTF写入的) |
4.2 ObjectOutputStream
ObjectOutputStream是源为对象的字节输出流,主要用来将对象序列化,可以通过如下方式构建:
public ObjectOutputStream(OutputStream out) throws IOException与DataOutputStream类似,ObjectOutputStream也提供了基础类型数据写入字节流的方法,除此之外主要提供了用来实现对象序列化的writeObject方法
| S.N. | 方法 | 说明 |
| 1 | public void write(int val) throws IOException | 写入一个字节 |
| 2 | public void write(byte[] buf) throws IOException | |
| 2 | public void write(byte[] buf, int off, int len) throws IOException | |
| private void writeArray(Object array, ObjectStreamClass desc, boolean unshared) | ||
| 3 | public void writeBoolean(boolean val) throws IOException | 写入一个字节,如果值为true,则写入1,否则0 |
| 4 | public void writeByte(int val) throws IOException | |
| 5 | public void writeBytes(String str) throws IOException | |
| 6 | public void writeChar(int val) throws IOException | |
| 7 | public void writeChars(String str) throws IOException | |
| 8 | public void writeDouble(double val) throws IOException | |
| 9 | public void writeFloat(float val) throws IOException | |
| 10 | public void writeInt(int val) throws IOException | 写入四个字节,最高位字节先写入,最低位最后写入 |
| 11 | public void writeLong(long val) throws IOException | |
| 12 | public final void writeObject(Object obj) throws IOException | |
| 13 | public void writeShort(int val) throws IOException | |
| 14 | public void writeUTF(String str) throws IOException | 将字符串的UTF-8编码字节写入,这个编码格式与标准的UTF-8编码略有不同 |
4.3 示例
@SneakyThrows
public static void main(String[] args) {
try (OutputStream fileOutputStream = new FileOutputStream("d:/student.dat");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream)) {
Student student = new Student("Michael", 23, 1);
objectOutputStream.writeObject(student);
}
try (InputStream fileInputStream = new FileInputStream("d:/student.dat");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream)) {
Student student = (Student) objectInputStream.readObject();
System.out.println(student);
}
}通过ObjectOutputStream像对象的序列化结果写入到文件中,然后通过ObjectInputStream反序列化,运行结果:
Student(name=Michael, age=23, grade=1.0)按照之前讲的字符文件和二进制文件的定义,上述序列化得到的文件就是二进制文件了(可以记事本打开看一下,会乱码,因为除了对象内容外,还有很多控制信息)。对象序列化就是将对象按照某种规则转为另一种形式(比如字节流,字符串),以方便存储,传播。但序列化则是序列化的逆过程,按照约定的规则解析序列化结果,得到序列化前的对象。除了Java默认提供的ObjectInputStream/ObjectOuputStream可以实现序列化/反序列化之外,还有很多工具可以同样可以实现,并且使用起来时间效率和空间效率要比ObjectInputStream/ObjectOuputStream要好,比如Hession、FastJson、Gson、Protobuf等,特别是谷歌提供的Protobuf,在近年来应用很广泛,这里不继续介绍了,之后打算专门写一篇关于Protobuf的文章介绍一下,有兴趣的同学也可以去了解一下:Google Protocol Buffers
参考链接:
1. JDK源码
2. 《Java编程的逻辑 》